
Tous les sites dynamiques et application web fonctionnent avec une base de données1 qui assure le traitement et la gestion des données. La base de données est indispensable au bon fonctionnement d’un site ou d’une application. Avec l’avènement des dispositifs numériques (sites, applications, cloud…), il faut traiter de grandes quantités de données, c’est la raison pour laquelle un certain nombre de systèmes de gestion de base de données différents ont vu et continuent de voir le jour.
Une base de données relationnelle est un système où les données sont organisées dans des tables. Les tables communiquent entre elles indirectement via les relations établies entre les données par un principe de cascade2. La base mathématique des bases de données relationnelle est l’algèbre relationnel permettant une réalisation concrète des requêtes exprimées en calcul relationnel.
Il existe pour gérer ce type de base de données des des systèmes de gestion, parmi lesquels MySQL, PostgreSQL, Oracle Database, etc.
Ce système de gestion de base de données est conçu pour maintenir en permanence une cohérence et une intégrité des données.
L’histoire des bases de données remonte aux années 1960, au moment où les premiers systèmes de gestion de bases de données (SGBD) commencent à faire leur apparition. Avant l’émergence des bases de données relationnelles, les systèmes de gestion de bases de données étaient principalement basés sur des modèles hiérarchiques ou en réseau.
Le besoin d’un modèle de données plus flexible et intuitif a conduit à l’introduction du modèle relationnel par Edgard F. Codd, un informaticien britannique qui a publié un article en 1970 intitulé « A Relational Model of Data for Large Shared Data Banks3 » à ce sujet. Dans cet article, Codd a présenté les principes fondamentaux du modèle relationnel, y compris les concepts de tables, de lignes, de colonnes et de clés. Il a également introduit des opérations relationnelles comme la sélection, la projection et la jointure, qui sont devenues des pierres angulaires du langage SQL.

À la suite des travaux de Codd, les premiers systèmes de gestion de bases de données relationnelle (SGBDR) ont été développés dans les années 1970. Les SGBDR ont progressivement gagné en popularité dans les années 1980 et 1990, avec des produits commerciaux comme Oracle, IBM DB2 et Microsoft SQL Server. Ces SGBD ont bien évolué au cours des dernières années ce qui leur offre une meilleure fiabilité et de meilleures performances.
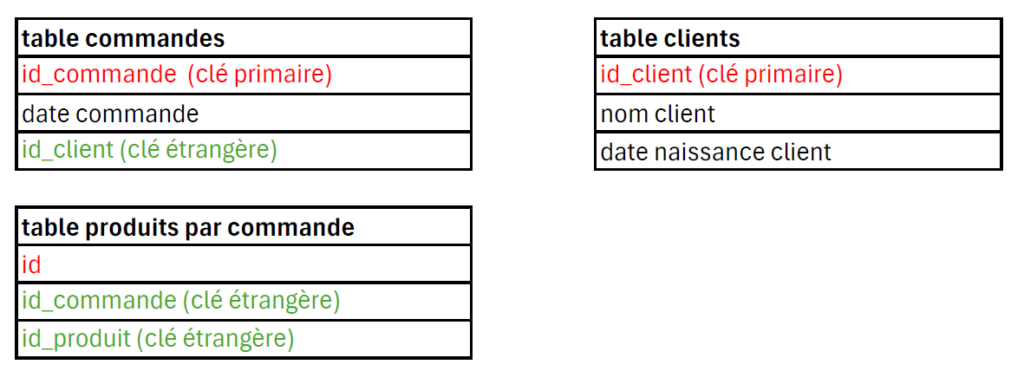
Une base de donnés relationnelle fonctionne avec des tables qui communiquent entre elles. Chaque table contient des colonnes (ou attributs), et des lignes. Chaque ligne dans une table est désignée par le terme « enregistrement ». Ce terme est couramment utilisé pour décrire une entrée individuelle ou une instance de données dans une table. Un enregistrement est identifiable à travers un identifiant unique auto-incrémenté (clé primaire). Une donnée (contenue dans une colonne) peut être : une chaine de caractères, des chiffres, un fuseau horaire (timestamp), une valeur nulle… Les données sont organisées à travers un ensemble de tables de façon très structurée, de sorte à éviter la redondance, c’est ce que l’on appelle la normalisation, cela améliore par la même occasion les performances. On ne répète pas une donnée inutilement, sur un site e-commerce, les catégories de produits figurent dans une table distincte, de sorte à ne pas devoir les répéter pour chacun de leur produit, ainsi, pour chaque produit enregistré, seul l’ID de la catégorie figurera sur sa ligne d’enregistrement. Autre exemple : lors d’une commande qui peut inclure plusieurs produits, on ne fera pas mention de la clé étrangère correspondant à l’identifiant du client dans la table des produits par commande dans la mesure où la clé étrangère mentionnant le client figure déjà dans la table listant les commandes.
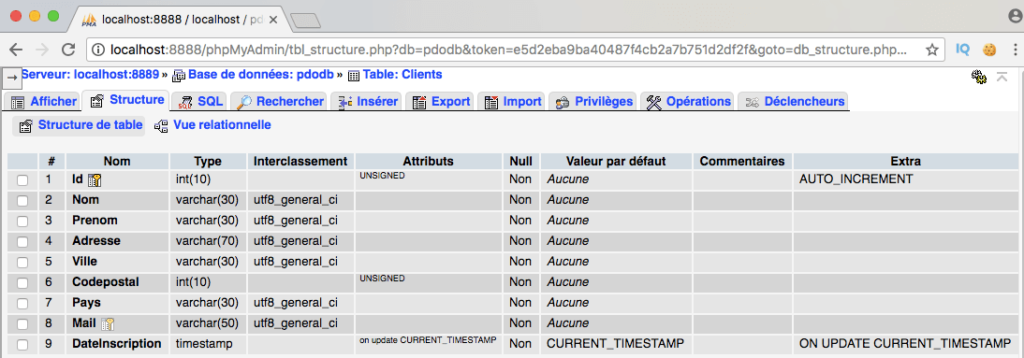
Pour que l’utilisation d’une base de données relationnelle soit pertinente, il faut que les tables de cette dernière communiquent entre elles. Pour référencer une donnée d’une autre table, on utilise une clé étrangère. Cette clé étrangère correspond à la clé primaire de la donnée dans sa table d’origine. Plus on ajoute de tables à la base de données, plus il y aura de relations entre les données.
La cascade simplifie la maintenance en réduisant la quantité de code nécessaire pour maintenir la cohérence des données entre les tables, les actions sur une table se propageant automatiquement aux tables liées. Elle renforce également l’intégrité référentielle4 en assurant que les modifications des clés primaires des tables parentes sont reflétées dans les clés étrangères des tables enfants, garantissant ainsi une intégrité solide. En automatisant les actions telles que la suppression ou la mise à jour des données liées les modifications dans les tables associées sont synchronisées. Cela réduit le risque d’erreurs humaines, comme l’oubli de mettre à jour les données liées après une modification. Les opérations de maintenance et de gestion des données sont simplifiées.
Les transactions représentent des séquences d’opérations, dans le but d’accomplir une tâche (insertion de données dans une ou plusieurs tables, la mise à jour de données existantes, la suppression de données). La transaction garantit donc que toutes ces opérations sont exécutées de manière cohérente et fiable, conformément aux propriétés ACID, afin de maintenir l’intégrité des données de la base de données. La propriété ACID (Atomicité, Cohérence, Isolation, Durabilité) définit les caractéristiques essentielles des transactions.
Le principe ACID est essentiel pour maintenir l’intégrité et la cohérence des données dans les bases de données relationnelles, ce qui est particulièrement important lorsque l’on sait que la précision des données est cruciale.
Il existe de nombreux outils de conception5 qui permettent de schématiser la base de données et de projeter les relations entre les tables, à l’aide d’un schéma entité-relation (ER), conçu par Peter Chen en 1976. Dans le processus de conception d’une bases de données relationnelles, on s’aide de modèles conceptuels et logiques.
Les logiciels de schématisation de bases de données6 relationnelles offrent une gamme de fonctionnalités pour simplifier la conception, la gestion et la documentation des bases de données. Ils permettent de créer des diagrammes représentant la structure des tables et les relations entre elles, de générer des scripts SQL automatiquement, de réaliser du reverse engineering7 pour importer une structure de base de données existante, de documenter automatiquement la structure de la base de données, de faciliter la collaboration entre plusieurs utilisateurs et de valider les schémas pour garantir le respect des bonnes pratiques de conception.
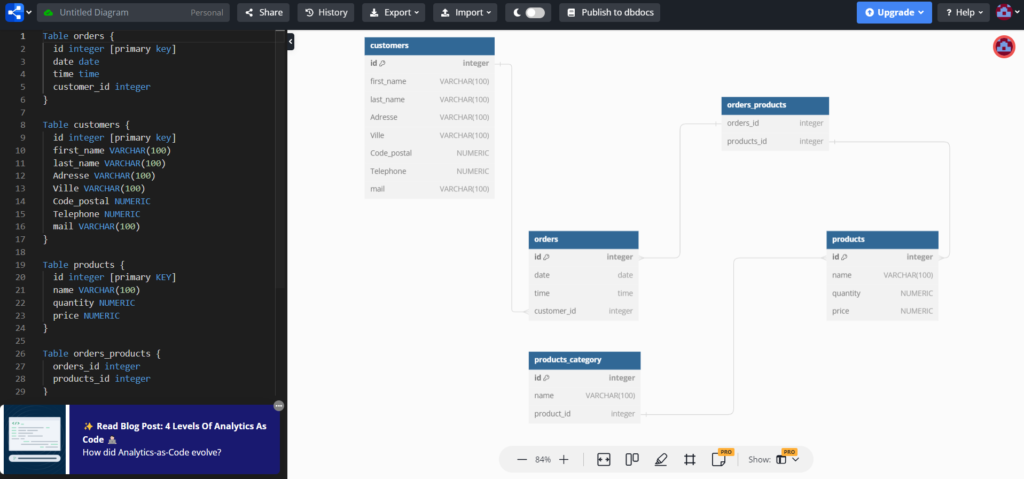
Un Modèle de Conceptualisation de Données (MCD) utilise des entités et des relations, déterminées par des cardinalités qui spécifient les associations entre les tables. Les cardinalités (1, n) définissent le nombre minimal et maximal d’instances dans une relation, orientant la conception de la base de données. Elles permettent la création de clés étrangères pour une Contrainte d’Intégrité Fonctionnelle (CIF) et de tables intermédiaires pour une Contrainte d’Intégrité Multiple (CIM), facilitant ainsi la transition du MCD à la mise en œuvre de la base de données via SQL. Une cardinalité décrit la nature de la relation entre les données.
Les cardinalités possibles se déclinent comme suit :
Les requêtes SQL sont des instructions envoyées à la base de données via un invite de commandes. Ces instructions permettent d’interagir avec la base de données et d’y effectuer des opérations (ajouter, supprimer une table, modifier sa structure, et de même pour chacune des données). Les requêtes SQL permettent aussi de chercher plusieurs données pour les afficher d’une façon facilement compréhensible et claire pour un humain. Par exemple, sur un site e-commerce, lorsque l’on filtre les produits, il y a des requêtes envoyées à la base dans le but d’afficher les produits souhaités par l’utilisateur. Si un utilisateur veut consulter une commande, un ensemble de requêtes iront chercher les données des différentes tables qui permettent le bon fonctionnement des commandes (les adresses, les identifiants des produits, la date et l’heure de la commande).
Voici un exemple de requête SQL qui sélectionne toutes les entrées de la table « produits » où la catégorie est « Electronique » :
SELECT *
FROM produits
WHERE categorie = 'Electronique'Les requêtes sont souvent longues et complexes (cela dépend des données que l’on cherche, de la façon dont on veut les trier, et de la façon dont on veut les manipuler). C’est la raison pour laquelle des clauses dans les requêtes SQL sont mobilisées, elles permettent de filtrer, trier, regrouper ou limiter les données récupérées dans la base. Parmi ces clauses : SELECT, FROM, WHERE, ORDER BY, GROUP BY, HAVIN, et LIMIT.
Tout système de gestion de base de données a des avantages et des inconvénients. Il ne convient donc pas de faire usage du modèle relationnel dans toutes les situations. En fonction de la facilité de rédaction des requêtes, de la quantité et des types de données, de la capacité de normalisation et de la simplicité d’organisation de ces dernières dans les tables, on va privilégier l’utilisation d’une base de données relationnelle ou se diriger vers d’autres systèmes de gestion de base de données plus complexes.
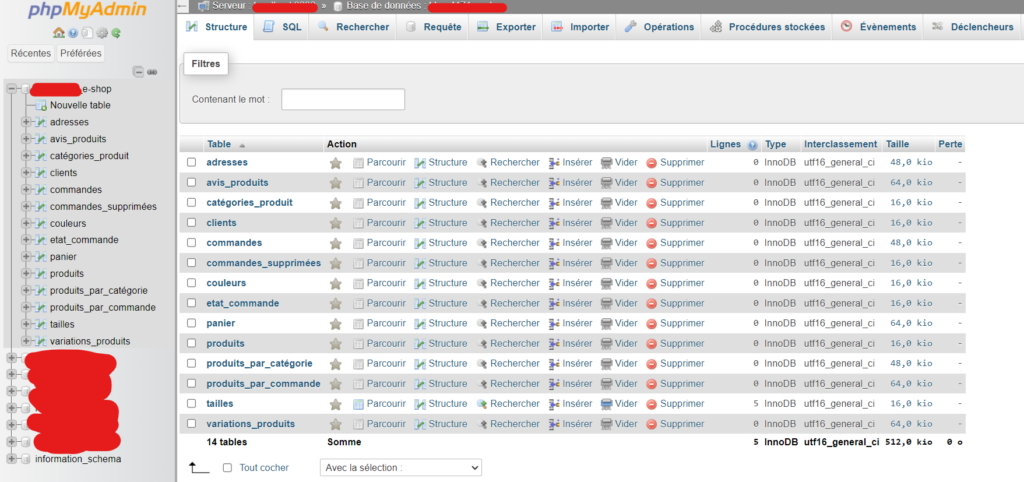
Certains outils offrant des interfaces graphiques claires aux utilisateurs permettent d’administrer facilement une base de données. Ces derniers peuvent gérer la base de données (tables, données, relations…) à l’aide des fonctionnalités offertes par l’outil en quelques clics, ou bien exécuter des requêtes pour cela, via un invite de commande. Par exemple : PHPMyAdmin qui fonctionne avec MySQL ou pgAdmin qui fonctionne avec PostgreSQL.
Les bases de données relationnelles sont structurées et privilégient la cohérence des tables pour optimiser le stockage garantir l’intégrité des données. Les transactions sont régies par le principe ACID. Les relations entre les tables avec un système de clé primaire et clé étrangère (index) sont indispensables à l’usage de ce système de gestion de bases de données.
D’autres systèmes de gestion de base de données existent tels que le NoSQL, plus flexibles, ils permettent de gérer de grandes quantités de données avec des performances adéquates, sans limite de contrainte dans la structure de la base. Leur fonctionnement est différent du modèle relationnel. On est incité à dupliquer les données, plutôt que de créer des relations afin d’optimiser les requêtes, cela est plus rapide mais utilise davantage de mémoire, ces bases de données privilégient la disponibilités à l’intégrité des données.